How Real-Time AI Voice Changing Works: Technology, Process, and Real-World Impact
Real-time AI voice changing is no longer a futuristic concept reserved for science fiction movies or research labs. Today, it powers live game streaming, virtual meetings, AI call centers, and content creation workflows around the world. Yet for many users and businesses, one fundamental question remains unanswered: how does real-time AI voice changing actually work?
This article breaks down the technology behind real-time AI voice changing in a clear, human, and practical way. We will explore the underlying AI models, the step-by-step transformation process, and the technical challenges involved, so you can make informed decisions when choosing AI voice solutions for personal or business use.
Introduction to Real-Time AI Voice Changing
At its core, real-time AI voice changing refers to the ability of artificial intelligence systems to modify a person’s voice instantly as they speak, without noticeable delay. Unlike traditional voice changers that simply adjust pitch or speed, modern AI-driven systems analyze and reconstruct speech using deep learning models trained on massive voice datasets.
The demand for this technology has surged in recent years. According to a 2024 report by MarketsandMarkets, the global voice AI market is projected to exceed $49 billion by 2030, driven by applications in gaming, customer service automation, and digital content creation. Real-time voice transformation is one of the fastest-growing segments within this market.
However, achieving high-quality voice conversion in real time is technically complex. AI systems must balance accuracy, naturalness, and ultra-low latency, all while running on consumer-grade hardware or cloud infrastructure.
What Is Real-Time AI Voice Changing?
Definition and Core Concept
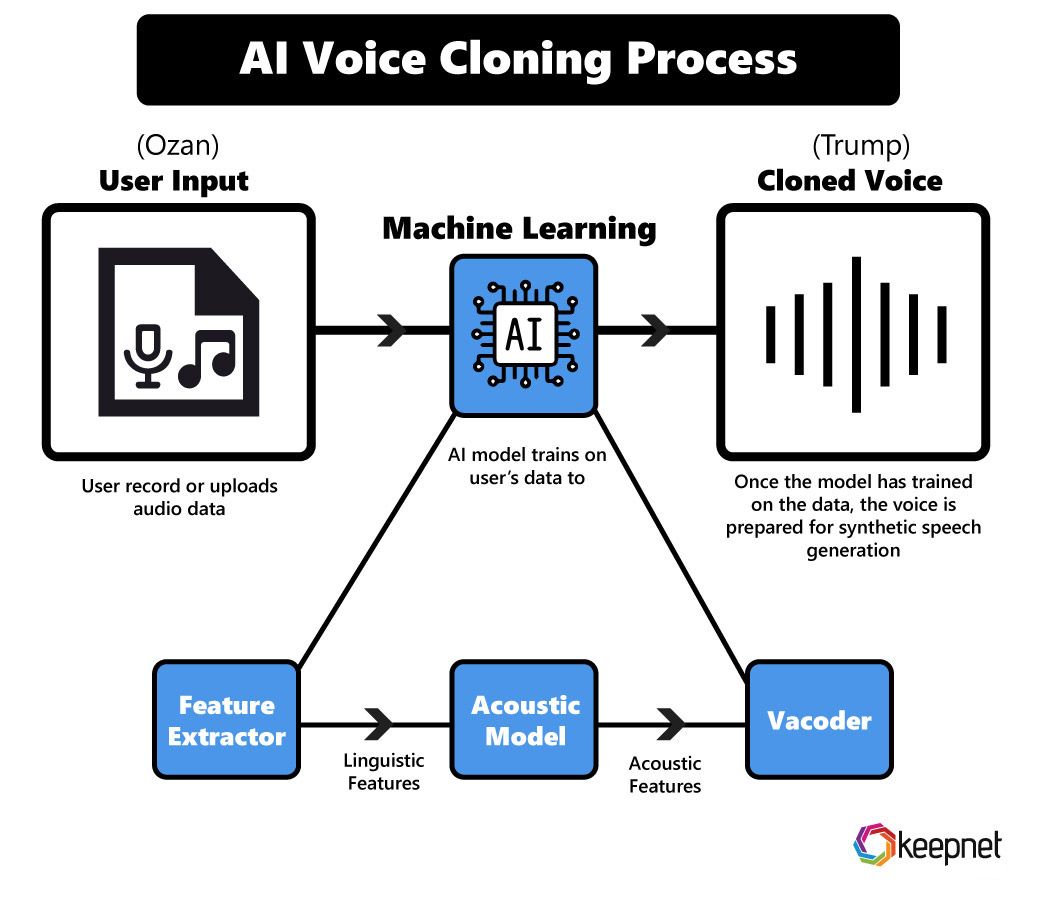
Real-time AI voice changing is a process where an AI system captures live speech, analyzes its acoustic features, and transforms it into a different voice profile while the user is still speaking. The transformed audio is then output almost instantly, typically within 20–50 milliseconds.
This process involves three fundamental stages:
- Voice capture: Recording raw audio input from a microphone.
- AI-driven transformation: Converting vocal features using trained neural networks.
- Real-time audio synthesis: Reconstructing and outputting the modified voice.
The defining feature is speed. If the system introduces noticeable delay, it breaks conversational flow and becomes unusable for live interactions such as gaming, meetings, or customer calls.
Real-Time vs. Pre-Recorded Voice Conversion
It is important to distinguish real-time AI voice changing from pre-recorded voice conversion. While both use similar AI models, their technical requirements differ significantly.
| Criteria | Real-Time Voice Changing | Pre-Recorded Voice Conversion |
|---|---|---|
| Latency tolerance | Extremely low (under 50 ms) | High (seconds or minutes acceptable) |
| Processing complexity | Optimized, lightweight models | Heavier, more detailed models |
| Use cases | Live calls, gaming, streaming | Dubbing, audiobooks, film |
This distinction explains why some AI voice tools sound excellent on recorded audio but struggle in live scenarios.
Core Technologies Behind Real-Time AI Voice Changing
Audio Signal Capture and Pre-Processing
The journey begins with raw audio input. A microphone captures the speaker’s voice and converts sound waves into a digital signal. Before AI processing begins, the system performs essential pre-processing steps:
- Noise reduction to remove background sounds
- Volume normalization for consistent input levels
- Frame segmentation, where audio is split into tiny time slices (often 10–20 ms)
This stage is crucial. Poor input quality leads to distorted output, regardless of how advanced the AI model is.
Feature Extraction from Human Voice
Instead of working with raw audio alone, AI systems extract key vocal features that define how a voice sounds. These features include:
- Pitch (F0): The perceived highness or lowness of a voice
- Timbre: The unique tone color that distinguishes one voice from another
- Formants: Resonant frequencies shaped by the vocal tract
- Phonemes: The smallest units of speech sound
By separating “what is being said” from “how it sounds,” AI can preserve speech content while altering vocal identity.
Neural Networks Used in Voice Changing
Modern real-time AI voice changing relies on deep learning models trained on thousands of hours of voice data.
Deep Learning Models
The most common architectures include:
- Autoencoders: Compress voice features and reconstruct them in a new style
- GANs (Generative Adversarial Networks): Improve realism through adversarial training
- Transformer-based models: Capture long-range speech patterns with high accuracy
According to research published by IEEE, transformer-based voice models have reduced voice conversion artifacts by over 30% compared to earlier architectures.
Voice Conversion vs. Voice Cloning
These two terms are often confused but represent different approaches:
- Voice conversion: Transforms a source voice into a target style without copying a specific individual
- Voice cloning: Replicates a particular person’s voice, often requiring consent and ethical safeguards
For real-time applications, voice conversion is more commonly used due to lower data requirements and faster processing.
Step-by-Step Process of Real-Time AI Voice Changing
Step 1: Live Voice Input
The system continuously captures audio from the user’s microphone. To maintain natural conversation, most platforms aim for end-to-end latency below 40 milliseconds, which is generally imperceptible to the human ear.
Step 2: AI Feature Mapping
Next, the extracted vocal features are mapped to a target voice profile. This is where the AI determines how your voice should sound after transformation, whether deeper, higher, robotic, or entirely synthetic.
Advanced systems also preserve emotional cues such as excitement or calmness, ensuring the output voice feels expressive rather than flat.
Step 3: Neural Voice Transformation
The AI model replaces the original timbre and pitch characteristics with those of the target voice. Unlike simple pitch shifters, this process reconstructs speech at a structural level, resulting in far more natural output.
As Dr. Rupal Patel, speech science expert at Northeastern University, notes:
“True voice transformation is not about changing pitch. It’s about reshaping how sound resonates through a virtual vocal tract.”
This insight explains why AI-based systems outperform traditional audio effects, especially in real-time scenarios.
Step 4: Real-Time Audio Synthesis
Once the neural model has transformed the voice features, the system must reconstruct them into an audible waveform. This process is known as audio synthesis. In real-time AI voice changing, synthesis engines are optimized for speed, often using neural vocoders such as WaveRNN or lightweight variants of HiFi-GAN.
The challenge here is precision under pressure. The system must generate natural-sounding audio without audible glitches, pops, or robotic artifacts, all while processing audio frames in milliseconds.
To achieve this, modern platforms rely on:
- Short audio buffers to minimize delay
- Parallel GPU or edge-based processing
- Dynamic quality adjustment based on system load
Step 5: Output Delivery and Integration
The final synthesized voice is delivered instantly to the output channel. This could be a headset, speakers, or a virtual audio device integrated with third-party platforms such as Zoom, Discord, Microsoft Teams, or in-game chat systems.
For business environments, real-time AI voice changing is often integrated directly into call center software, enabling:
- Brand-consistent AI agent voices
- Live language adaptation
- Voice anonymization for privacy compliance
At this stage, the user experiences what feels like a seamless, natural conversation, unaware of the complex AI pipeline running beneath the surface.
Why Low Latency Is Critical in Real-Time Voice AI
Latency refers to the time delay between speaking and hearing the transformed voice. In real-time communication, even small delays can disrupt conversation flow and cause cognitive discomfort.
Research from Google’s Human-Computer Interaction team suggests that humans begin to notice conversational disruption at delays above 100 milliseconds. As a result, most real-time AI voice changing systems aim for latency under 50 milliseconds.
To achieve this, AI developers use several optimization strategies:
- Model compression and pruning
- Hardware acceleration using GPUs or NPUs
- Edge computing instead of distant cloud servers
Low latency is not just a technical benchmark. It directly determines whether a voice-changing system feels usable, professional, and trustworthy.
Common Use Cases of Real-Time AI Voice Changing
Gaming and Live Streaming
Gamers and streamers were among the earliest adopters of real-time AI voice changing. The technology allows players to role-play characters, protect personal identity, or enhance entertainment value during live broadcasts.
Popular use cases include:
- Character-based voice personas
- Privacy protection in competitive gaming
- Interactive audience engagement
Business and Customer Support
In the enterprise world, real-time AI voice changing enables scalable, consistent voice interactions. Companies can deploy AI-powered voice agents that maintain a unified brand voice across thousands of customer interactions.
According to Gartner, by 2026, over 70% of customer interactions will involve AI-assisted voice or chat technologies.
Key benefits include:
- Reduced operational costs
- 24/7 customer availability
- Improved multilingual support
Content Creation and Media Production
Content creators use real-time AI voice changing for podcasts, videos, and live shows. Instead of hiring multiple voice actors, creators can switch vocal styles instantly.
This has democratized content production, enabling small teams to create professional-grade audio experiences.
Accessibility and Privacy Protection
Another growing application is accessibility. Real-time voice AI can help users with speech impairments communicate more clearly, or anonymize voices in sensitive environments such as online support groups or journalism.
Limitations and Challenges of Real-Time AI Voice Changing
Despite its rapid progress, real-time AI voice changing is not without challenges:
- Audio artifacts: Especially under poor network or hardware conditions
- High computational demand: Quality improves with better hardware
- Ethical concerns: Risk of misuse without proper safeguards
Responsible platforms address these risks through user verification, watermarking, and transparent usage policies.
How to Choose the Right Real-Time AI Voice Changer
Key Evaluation Criteria
When evaluating AI voice solutions, consider the following factors:
- Voice naturalness and emotional expression
- Latency performance in real-world conditions
- Customization and voice style options
- Language and accent support
- Clear and transparent pricing
Why Use an AI Comparison Platform
The AI market is crowded, and marketing claims often exaggerate capabilities. A trusted comparison platform helps users make informed decisions based on real features and verified performance.
ai.duythin.digital was built to solve this exact problem. The platform provides in-depth reviews, feature comparisons, and transparent pricing insights curated by Vietnam’s leading AI community, saving users hours of research.
Future of Real-Time AI Voice Changing
The future of real-time AI voice changing is deeply tied to advances in emotional intelligence and personalization. Emerging trends include:
- Emotion-aware voice synthesis
- Cross-language real-time voice conversion
- Hyper-personalized AI voice identities
- Integration with virtual assistants and the metaverse
As models become more efficient, real-time voice AI will move from novelty to everyday infrastructure.
Conclusion: Key Takeaways
Real-time AI voice changing works by combining advanced audio processing, deep learning models, and ultra-low latency systems to transform human speech instantly. From gaming and content creation to enterprise customer support, the technology is reshaping how we communicate.
Understanding how it works empowers users and businesses to choose the right tools, avoid overhyped solutions, and deploy voice AI responsibly.
Frequently Asked Questions (FAQ)
Is real-time AI voice changing safe to use?
Yes, when used on reputable platforms with clear privacy policies and ethical safeguards.
Does real-time voice changing require expensive hardware?
Not necessarily. Many modern solutions run efficiently on consumer devices or cloud infrastructure.
Can AI voice changing sound completely natural?
High-quality systems can achieve near-human realism, though results depend on model quality and input conditions.
Is voice cloning legal?
Voice cloning typically requires consent. Ethical platforms clearly distinguish it from general voice conversion.
Call to Action
If you are exploring real-time AI voice changing for personal use or business deployment, avoid guesswork and marketing noise.
Visit ai.duythin.digital to compare AI voice tools, read expert reviews, and access transparent pricing insights trusted by Vietnam’s AI community.