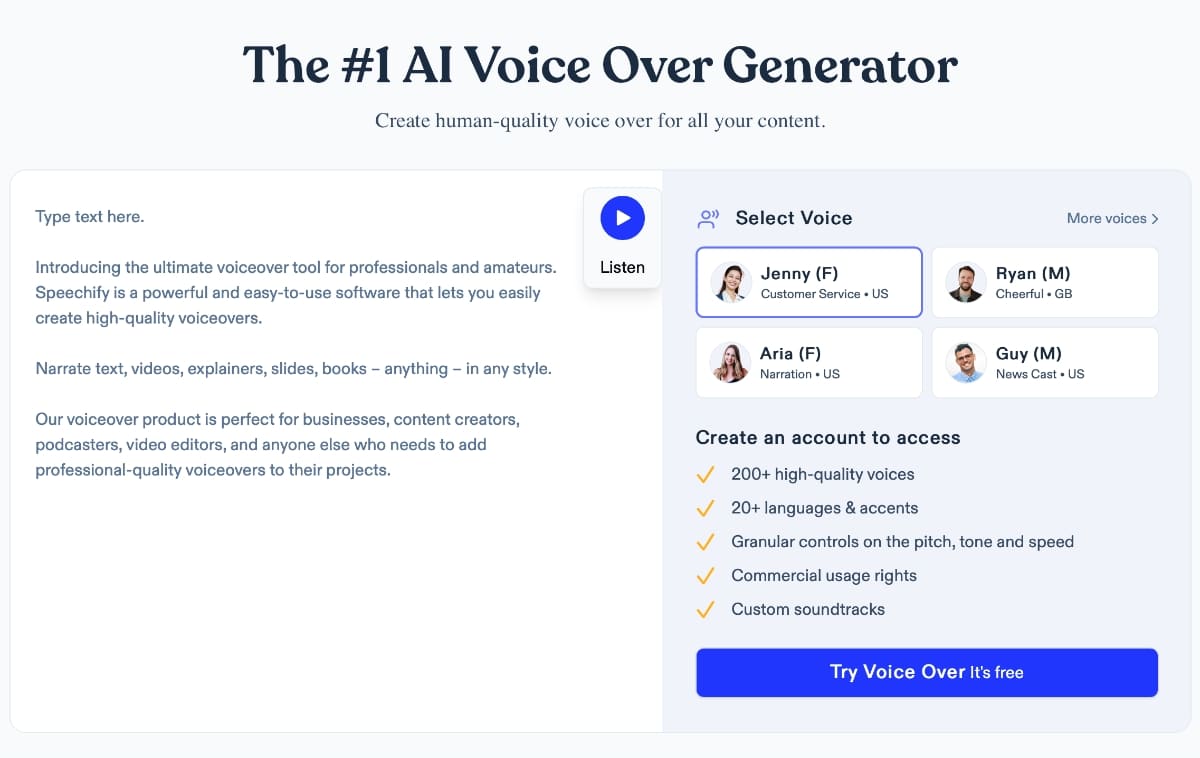
Realistic AI Voice Generator: How Human-like Voices Are Created
Imagine listening to an audiobook, a podcast, or a customer service assistant and forgetting for a moment that the voice you hear is not human. That moment of doubt is no accident. It is the result of years of advances in artificial intelligence, linguistics, and deep learning. Today, the realistic AI voice generator has evolved from robotic, monotone speech into expressive, natural-sounding voices that can inform, persuade, and even comfort listeners.
As businesses scale content production and individuals demand faster, more flexible creative tools, AI-generated voices are becoming a core part of digital communication. Yet many people still ask the same question: how do AI voices sound so human? This article answers that question in depth by breaking down the technology, science, and real-world systems behind realistic AI voice generation.
Written from an expert perspective and grounded in real industry practice, this guide is designed for business leaders, creators, developers, and AI enthusiasts who want to understand not just what AI voice generators do, but how they work and why they matter.
What Is a Realistic AI Voice Generator?
A realistic AI voice generator is a software system that converts written text into spoken audio that closely resembles human speech. Unlike early text-to-speech systems that sounded mechanical and flat, modern AI voice generators use neural networks trained on massive speech datasets to replicate human pronunciation, rhythm, emotion, and intonation.
The defining feature of a realistic AI voice generator is naturalness. Naturalness refers to how closely the generated voice matches human speech patterns, including subtle pauses, emphasis, breathing, and emotional tone. When done well, listeners struggle to distinguish AI speech from a human voice.
How AI Voice Generators Differ from Traditional Text-to-Speech
Traditional text-to-speech (TTS) systems relied on rule-based or concatenative methods. These systems stitched together pre-recorded audio clips based on linguistic rules. While functional, they often sounded unnatural because they lacked flexibility and contextual understanding.
Modern AI voice generators, by contrast, rely on deep learning and neural text-to-speech (Neural TTS). These systems do not simply piece together sounds. Instead, they learn how speech works by analyzing thousands of hours of recorded human voices.
- Traditional TTS: Rule-based, limited expressiveness, robotic tone
- Neural TTS: Data-driven, adaptive, highly human-like output
The Evolution of AI Voice Technology
The journey toward realistic AI voices has unfolded in several stages:
- Rule-Based Speech (1980s–1990s): Early systems followed linguistic rules with minimal variation.
- Statistical Parametric Speech (2000s): Introduced probability models but still lacked emotional depth.
- Neural Text-to-Speech (2016–present): Deep neural networks enabled fluid, expressive, and natural speech.
A landmark moment came in 2016 when DeepMind introduced WaveNet, a neural vocoder that dramatically improved speech realism. Since then, architectures like Tacotron, FastSpeech, and HiFi-GAN have pushed the boundaries even further.
How Human-like AI Voices Are Created
Behind every realistic AI voice generator is a multi-stage pipeline that transforms raw text into lifelike audio. While the mathematics and engineering are complex, the overall process can be understood in a clear sequence.
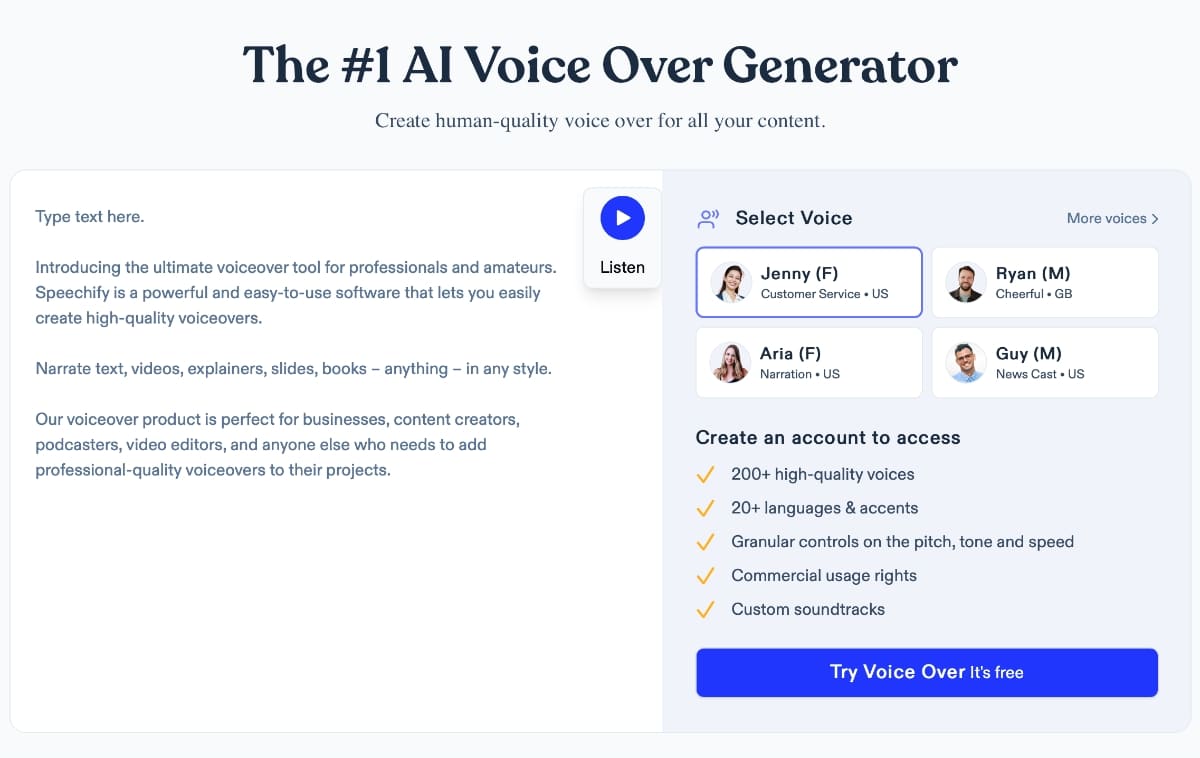
Step 1: Data Collection and Voice Datasets
High-quality data is the foundation of realistic AI voices. AI models are trained on large datasets containing recordings of real human speech. These recordings are carefully curated to capture a wide range of sounds, speaking styles, and emotional expressions.
A professional-grade dataset typically includes:
- Thousands of recorded sentences
- Clear pronunciation of phonemes
- Multiple speaking speeds and tones
- Emotional variations such as calm, excited, or serious speech
Why High-Quality Voice Data Matters
Poor-quality data leads to unnatural output. Background noise, inconsistent accents, or limited emotional range can all degrade realism. According to research published by IEEE, models trained on cleaner, more diverse datasets produce speech rated up to 30–40% more natural by human listeners.
This is why leading AI voice providers invest heavily in studio-quality recordings and professional voice actors. The better the data, the more human the result.
Step 2: Neural Text-to-Speech (Neural TTS)
Neural TTS is the core technology behind modern AI voice generation. Instead of following predefined rules, neural networks learn patterns directly from data. When given text, the model predicts how a human would naturally say it.
Most realistic AI voice generators use a two-part architecture:
- Text and linguistic analysis: Understanding the meaning and structure of the text
- Speech synthesis: Converting that understanding into sound
Text Analysis and Linguistic Modeling
Before generating sound, the AI analyzes the text. This step involves tokenization, pronunciation mapping, and prosody prediction. Prosody refers to rhythm, stress, and intonation, which are critical for natural speech.
For example, consider the sentence: “You’re coming today?” Depending on intonation, it can sound curious, surprised, or skeptical. Neural TTS models learn these nuances by studying real conversations.
Acoustic Modeling
Once the text is understood, the model converts it into an acoustic representation, usually a spectrogram. This visual-like representation captures pitch, tone, and timing. It acts as a blueprint for how the voice should sound.
Vocoder Technology: Turning Data into Sound
The final step is handled by a vocoder. Vocoders such as WaveNet or HiFi-GAN transform spectrograms into audible sound waves. This is where realism truly emerges.
Modern vocoders can generate audio with:
- Natural breathing patterns
- Smooth transitions between words
- Minimal digital artifacts
According to Google AI research, neural vocoders have reduced audible distortion by more than 50% compared to older methods, significantly improving listener trust and engagement.
The Science Behind Natural-Sounding AI Voices
Human speech is not just about words. It is shaped by rhythm, emotion, and subtle imperfections. Realistic AI voice generators aim to replicate these traits using sophisticated modeling techniques.
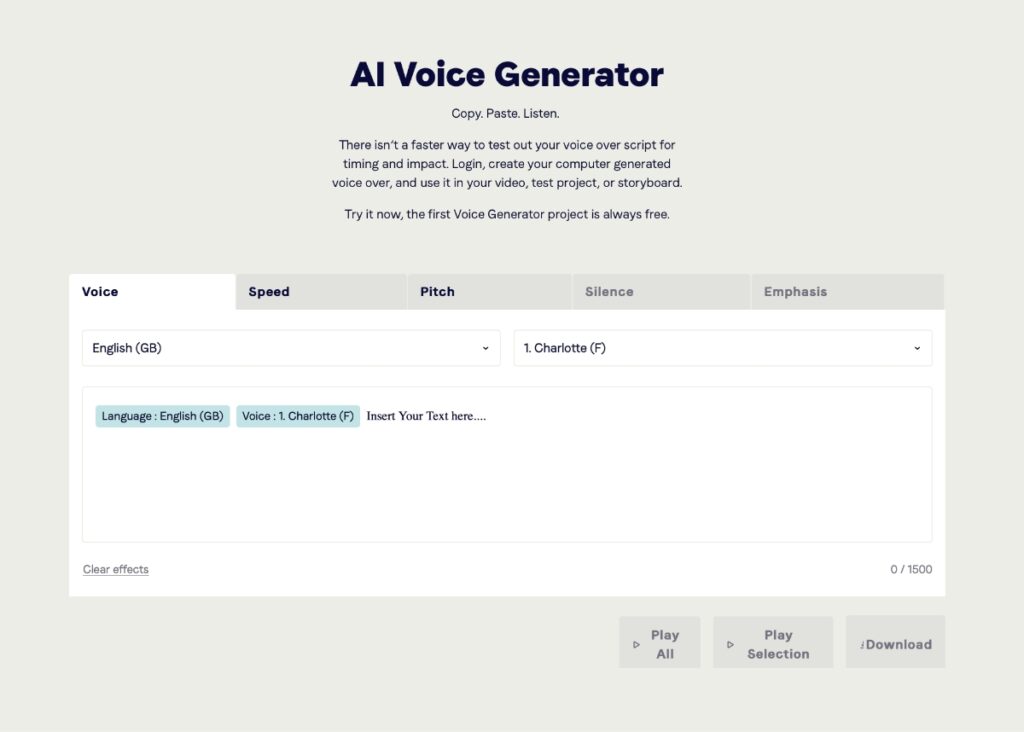
Prosody, Rhythm, and Intonation
Prosody is often what separates robotic speech from human-like voices. Neural models analyze how humans naturally vary pitch, slow down, speed up, and pause. These micro-adjustments make speech feel alive.
For example:
- Short pauses improve clarity and realism
- Pitch variation conveys emotion and intent
- Stress patterns guide listener attention
Emotional Modeling in AI Voices
Emotion is one of the most challenging aspects of speech synthesis. However, modern realistic AI voice generators can now produce voices that sound calm, enthusiastic, empathetic, or authoritative.
This is achieved by training models on emotionally labeled datasets. Each recording is tagged with emotional context, allowing the AI to learn how emotion affects tone and delivery.
“Emotion is not an add-on to speech. It is fundamental to how humans communicate meaning.”
— Professor Alan Black, Carnegie Mellon University, Speech Synthesis Researcher
Can AI Voices Truly Express Emotion?
While AI voices have improved dramatically, they are not perfect. Subtle emotional shifts and spontaneous reactions remain difficult to model. However, for structured content such as marketing videos, e-learning, and customer support, emotional AI voices are already highly effective.
Industry analysts predict that emotionally adaptive AI speech will become standard within the next five years as models gain more contextual awareness.
AI Voice Cloning Explained
AI voice cloning takes realism one step further. Instead of generating a generic voice, voice cloning creates a digital replica of a specific person’s voice. With enough data, an AI can reproduce unique vocal traits, accents, and speaking styles.

How AI Voice Cloning Works
Voice cloning models are trained on recordings from a single speaker. The AI learns the speaker’s vocal fingerprint, including pitch range, pronunciation habits, and pacing. Once trained, the system can generate new speech in that voice using any text input.
There are two main approaches:
- Multi-shot voice cloning: Requires hours of audio but delivers high accuracy
- One-shot voice cloning: Uses only a few minutes of audio with lower fidelity
As of recent benchmarks, multi-shot systems achieve significantly higher listener satisfaction, especially for long-form content.
In the next section of this article, we will explore ethical considerations, real-world applications, and how businesses and creators are using realistic AI voice generators today.
Ethical and Legal Considerations of AI Voice Technology
As realistic AI voice generators and voice cloning tools become more accessible, ethical and legal questions naturally follow. While the technology offers enormous value, it also introduces risks if used irresponsibly.
Consent and Voice Ownership
A human voice is a deeply personal biometric identifier. Ethical AI voice systems require explicit consent from the original speaker before their voice is recorded, trained, or cloned. Reputable providers clearly document consent policies and restrict unauthorized voice replication.
According to guidance from the World Economic Forum, transparent consent and traceability are essential to maintaining trust in generative AI systems.
Preventing Misuse and Deepfakes
One of the most discussed risks is the potential misuse of AI-generated voices for fraud, impersonation, or misinformation. To counter this, leading platforms now implement safeguards such as:
- Watermarking or audio fingerprinting
- Restricted voice cloning access
- Audit logs and usage monitoring
From an E-E-A-T perspective, trustworthy AI platforms are those that balance innovation with responsibility and user protection.
Real-World Applications of Realistic AI Voice Generators
The adoption of realistic AI voice generators is accelerating across industries. What was once experimental is now operational, delivering measurable efficiency and scalability.
Business and Marketing
Marketing teams use AI voices to create product explainers, social media ads, and localized campaigns at scale. Instead of hiring multiple voice actors for different languages or regions, a single AI system can generate consistent brand voice across markets.
A 2024 report by Gartner estimates that companies using AI-generated audio reduce content production costs by up to 60%.
Content Creation and Media
YouTubers, podcasters, and audiobook publishers rely on AI voices for narration, prototyping, and even final production. For creators, the key benefit is speed without sacrificing quality.
- Daily content production without burnout
- Consistent voice across episodes
- Rapid iteration and editing
E-Learning and Accessibility
Educational platforms use realistic AI voice generators to narrate courses, tutorials, and training materials. These voices improve accessibility for visually impaired learners and support multilingual education.
UNESCO highlights AI speech technology as a key enabler for inclusive digital education, especially in emerging markets.
Customer Support and Virtual Assistants
AI-powered voice assistants now handle customer inquiries, appointment scheduling, and outbound calls. Human-like voices increase user comfort and reduce frustration compared to robotic systems.
What Makes an AI Voice Generator Truly Human-like?
Not all AI voice generators are equal. Realism depends on several measurable and experiential factors that users should evaluate carefully.
Naturalness and Listening Comfort
Naturalness refers to how pleasant and fatigue-free the voice sounds over time. High-quality systems minimize repetitive patterns and unnatural timing.
Language and Accent Support
A realistic AI voice generator should support multiple languages and regional accents. This is especially important for global businesses and multicultural audiences.
Customization and Control
Advanced platforms allow users to adjust:
- Speaking speed
- Pitch and tone
- Emotional intensity
These controls enable fine-tuning for different contexts, from formal corporate narration to casual storytelling.
Comparing Popular Realistic AI Voice Generators
When evaluating AI voice tools, comparison saves time and reduces risk. Below is a simplified comparison of common evaluation criteria.
| Criteria | Basic TTS Tools | Advanced AI Voice Generators |
|---|---|---|
| Voice Realism | Low to medium | High, near-human |
| Emotion Support | Limited or none | Multi-emotion capable |
| Customization | Minimal | Extensive controls |
| Pricing Transparency | Often unclear | Clear, tier-based |
Platforms such as ai.duythin.digital specialize in aggregating detailed reviews, feature comparisons, and transparent pricing so users can make informed decisions without weeks of research.
How to Choose the Right AI Voice Generator for Your Needs
For Businesses
Businesses should prioritize scalability, consistency, and compliance. Look for solutions that integrate with existing workflows and offer enterprise-grade support.
For Individual Creators
Creators benefit most from ease of use, flexible pricing, and export options. A realistic AI voice generator should save time, not add complexity.
For Developers and Technical Teams
Developers should evaluate API stability, documentation quality, and latency. Reliable APIs enable real-time applications such as voice assistants and interactive systems.
The Future of Realistic AI Voice Technology
The future of AI-generated speech points toward even deeper personalization and emotional intelligence. Emerging trends include:
- Real-time emotion adaptation
- Context-aware conversational voices
- Hyper-personalized AI brand voices
Will AI Voices Replace Human Voice Actors?
Most experts agree the future is collaborative. AI voices handle scale and speed, while human voice actors remain essential for artistic, emotional, and high-stakes work.
“AI voices are not replacing humans. They are redefining how and where human creativity is applied.”
— MIT Technology Review, Generative AI Analysis
Frequently Asked Questions (FAQ)
Are realistic AI voice generators safe to use?
Yes, when used through reputable platforms that enforce consent, security, and ethical safeguards.
Can AI voices sound completely human?
In many use cases, listeners cannot reliably distinguish advanced AI voices from human recordings, especially for short or structured content.
Do I need technical skills to use an AI voice generator?
Most modern tools are designed for non-technical users, with intuitive interfaces and guided workflows.
How much does a realistic AI voice generator cost?
Pricing varies widely, from free tiers to enterprise subscriptions. Comparison platforms help clarify true costs and value.
Conclusion: Why Realistic AI Voices Matter
Realistic AI voice generators represent a major shift in how humans interact with technology. By combining deep learning, linguistic science, and ethical design, these systems enable scalable, natural communication across industries.
For businesses, creators, and developers alike, understanding how human-like AI voices are created is the first step toward using them effectively and responsibly.
If you want to explore trusted AI voice solutions, compare features, and see transparent pricing from Vietnam’s leading AI community, visit ai.duythin.digital. Save time on research and make confident decisions backed by real expertise.